A comment here https://stackoverflow.com/questions/12335784/c-integer-overflow postulated, the C-compiler would be able to optimize arithmetic expressions with undefined behavior (such as if (a -10 < 20) ) much better if the variable a being a signed integer (converting internally to an expression similar to a < 30). This is in contrast to the case variable a being an unsigned integer.
And indeed, there is a difference in the output of the C compiler (x86-64 clang 13.0.0), generating less instructions when declaring the variable a as signed integer int
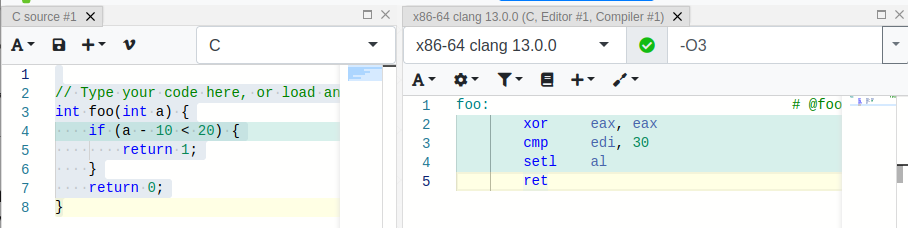
Compared to the output of the C-compiler when declaring as unsigned integer unsigned int
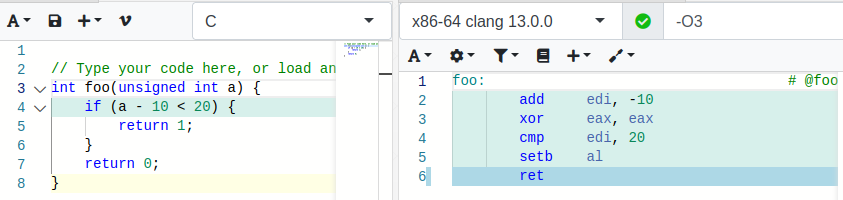
Explaining the code generation of the C compiler
As for the programming language C, the behavior of overflow/underflow is undefined: Garbage In, Garbage Out!
This means the compiler is not constrained by having to worry about what happens when there is overflow/underflow. It only has to emit an executable that exemplifies the behavior for the cases which are defined. For example in case of an overflow of a single signed integer variable, then the behavior of the complete application is said to be undefined!
Analyzing code generation of the Rust compiler
I wondered if there might be any difference in the output of the rust compiler (using -C opt-level=3) either declaring variable a as type i32 or type u32.
Using the Compiler Explorer https://rust.godbolt.org, the conclusion is:
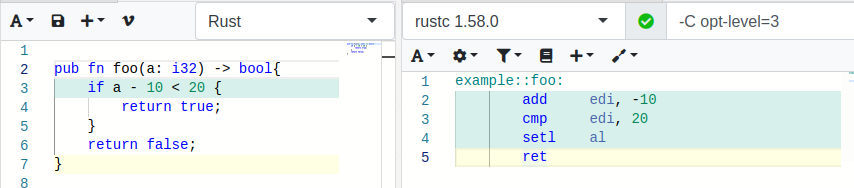
There is no difference! The Rust-Compiler does not transform the expression to something like a < 30 for the case using signed integers !
See the function using Signed Integer i32
See the function using Unsigned Integer u32
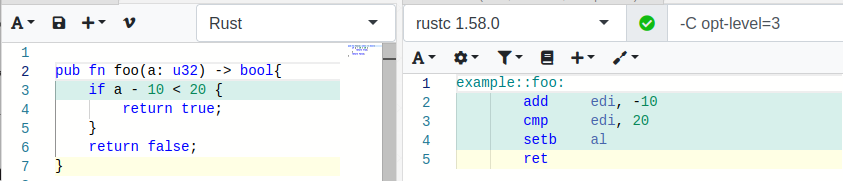
As it seems, this is not a lost opportunity for optimization of the signed case, but it is intended behavior, as these two statements are not equal in terms of integer underflow a - 10 < 20 and a < 30, where variable a being a signed integer. And for that reason Rust does not perform any optimization potentially changing the semantics of the expression.
For example, just assume a: i8 = -120 in this case the expression a - 10 would cause an underflow (wrapping) evaluating to value 126. In this case a - 10 < 20 would yield false, buta < 30 would yield true!!
So, whereas C is acting on the maxim “I think I know what you mean” and performing ruthless optimization, in contrast Rust is not changing the semantics when generating the binary code.
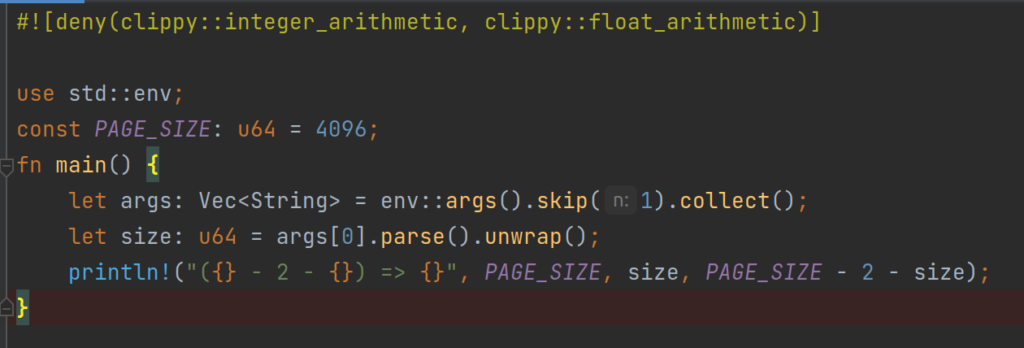
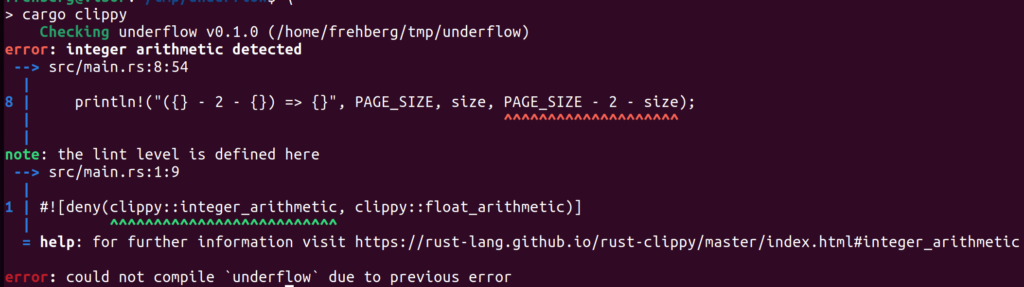
Now, to find these arithmetic expression with undefined behavior in your code, Rust clippy could be used. After installation of clippy, the following compiler attribute can be added to your lib or application
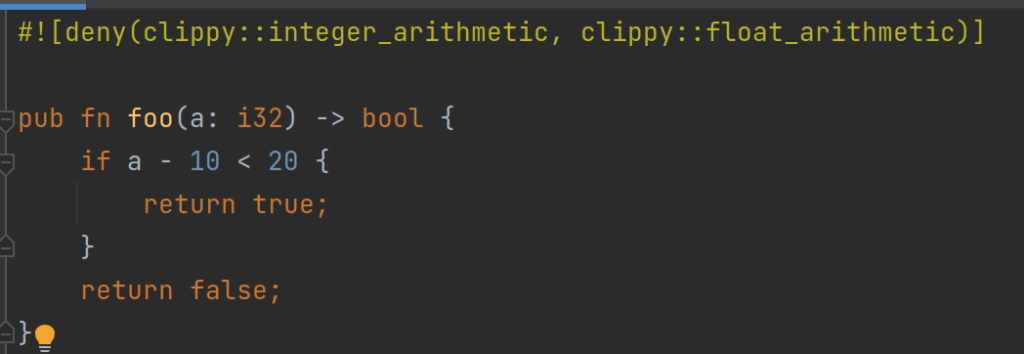
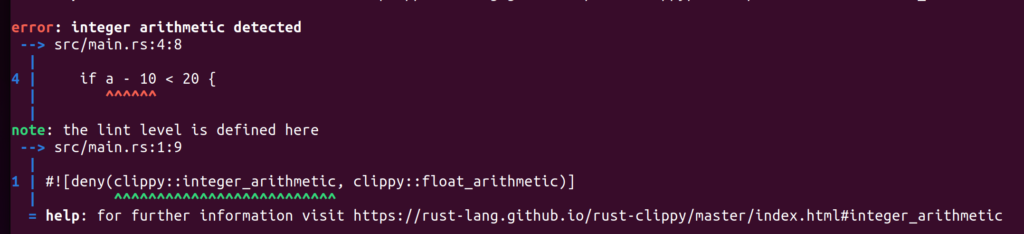
now calling cargo clippy the faulty location in question will be highlighted and could be corrected.
Conclusion
So, regarding arithmetic expression with undefined behavior, unlike C/C++ the Rust compiler is treating signed operations and unsigned operations the same. Those expressions with undefined behavior are not optimized by the compiler as this optimization might change the semantics of the code! Now, to find these spots in your Rust code, the compiler tool clippy can be used; either refactoring the code to get rid of the undefined behavior (see below), or handling these cases gracefully as shown in my previous post!
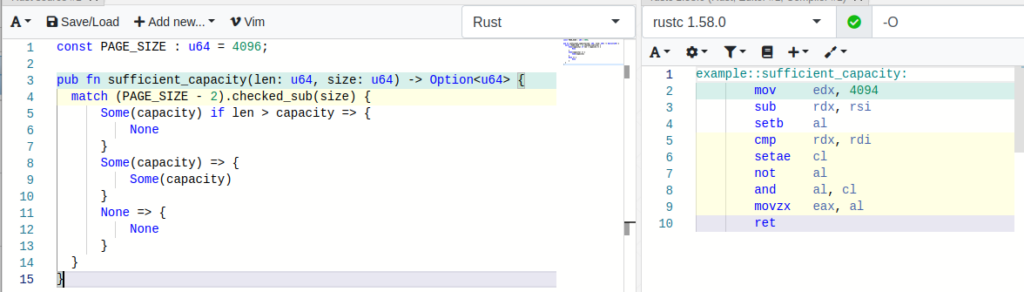
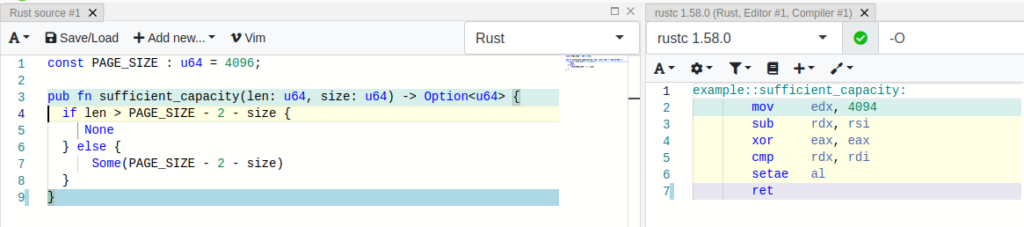
For example, using clippy the faulty expression a - 10 < 20 would be detected and could be changed to

PS: As dealing with acceptable and unacceptable input values, if you want to annotate functions and methods with “contracts”, using invariants, pre-conditions and post-conditions, check out the crate contracts – Design By Contract for Rust.
For example, using the crate contracts to define a pre-condition of the form “a >= 10“. Just, these constraints are not evaluated at compile time, but at runtime.