Recently a critical bug has been discovered in Linux Kernel https://seclists.org/oss-sec/2022/q1/55 , being caused by an unsigned integer underflow. I was wondering how the code in question would have been done safely in Rust, preventing such underflow.
At first, please read about the issue (citing the original post):
On 18 Jan 2022, at 18:21, Will <willsroot () protonmail com> wrote: There is a heap overflow bug in legacy_parse_param in which the length of data copied can be incremented beyond the width of the 1-page slab allocated for it. We currently have created functional LPE exploits against Ubuntu 20.04 and container escape exploits against Google's hardened COS. The bug was introduced in 5.1-rc1 (https://github.com/torvalds/linux/commit/3e1aeb00e6d132efc151dacc062b38269bc9eccc#diff-c4a9ea83de4a42a0d1bcbaf1f03ce35188f38da4987e0e7a52aae7f04de14a05) and is present in all Linux releases since. As of January 18th, this patch (https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=722d94847de29310e8aa03fcbdb41fc92c521756) fixes this issue. The bug is caused by an integer underflow present in fs/fs_context.c:legacy_parse_param, which results in miscalculation of a valid max length. A bounds check is present at fs_context.c:551, returning an error if (len > PAGE_SIZE - 2 - size); however, if the value of size is greater than or equal to 4095, the unsigned subtraction will underflow to a massive value greater than len, so the check will not trigger. After this, the attacker may freely write data out-of-bounds. Changing the check to size + len + 2 > PAGE_SIZE (which the patch did) would fix this. Exploitation relies on the CAP_SYS_ADMIN capability; however, the permission only needs to be granted in the current namespace. An unprivileged user can use unshare(CLONE_NEWNS|CLONE_NEWUSER) to enter a namespace with the CAP_SYS_ADMIN permission, and then proceed with exploitation to root the system.
As the Linux kernel has been implemented using the programming language C, these kind of integer underflows may happen undiscovered in the expression (PAGE_SIZE - 2 - size), using unsigned variables with PAGE_SIZE=4096 and if size>=4095.
Now, using the programming language Rust instead, we have got to distinguish different cases.
Behavior in Release Mode
If the application has been compiled with the flag –-release the underflow in the expression (PAGE_SIZE - 2 - size) might have occurred undiscovered as well. This flag causes the compiler to build artifacts in release mode, with optimization and without any checks for overflows or underflows.
For example, having this small Rust code snippet
use std::env;
const PAGE_SIZE: u64 = 4096;
fn main() {
let args: Vec<String> = env::args().skip(1).collect();
let size: u64 = args[0].parse().unwrap();
println!("({} - 2 - {}) => {}", PAGE_SIZE, size, PAGE_SIZE - 2 - size);
}
Here, the underflow of the unsigned 64-bit integer expression (PAGE_SIZE - 2 - size) would not be discovered in release mode, and producing the following output:
$ cargo run --release 4095
Compiling underflow v0.1.0 (test/underflow)
Finished release [optimized] target(s) in 0.28s
Running target/release/underflow 4095
(4096 - 2 - 4095) => 18446744073709551615
Behavior in Debug Mode
Otherwise, if the compiler flag --release is absent, the Rust compiler will produce artifacts in debug mode, including checks for arithmetic underflows and overflows. Now, using unit tests during development, such edge cases would have been discovered, hopefully.
For example, In debug mode an underflow in the expression (PAGE_SIZE - 2 - size) would trigger a panic and the application/test would abort with an error message similar to
thread 'main' panicked at 'attempt to subtract with overflow', src/xxx.rs:9:20
One can detect such arithmetic overflows/underflows in code automatically using rust-chippy! After installation of rust-clippy, just decorate your code as shown below
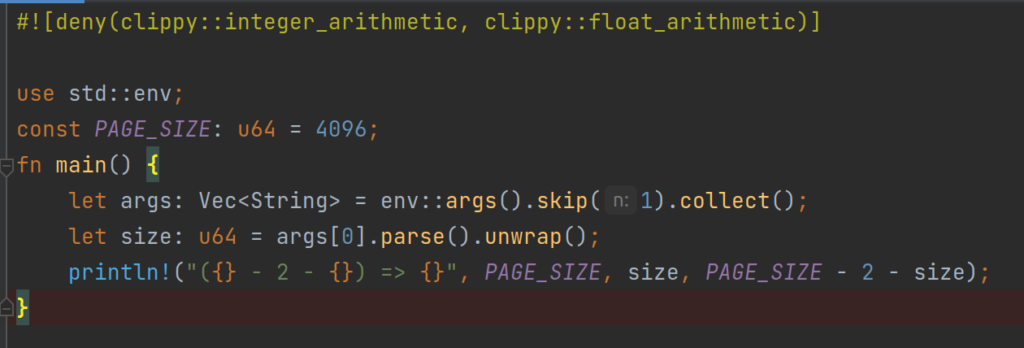
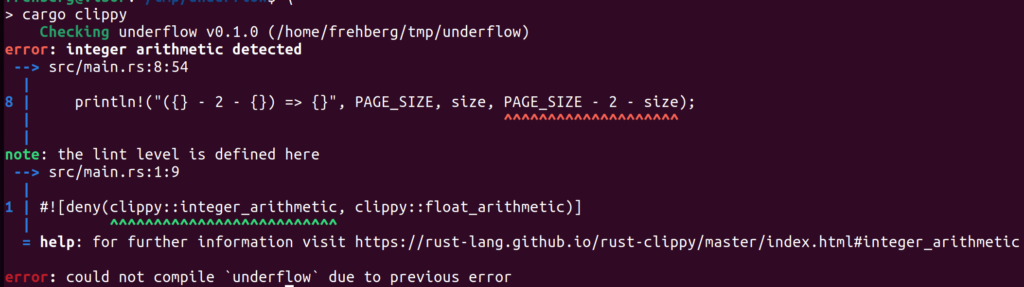
And now the following call cargo clippy will detect the arithmetic operation with undefined behavior, and clippy yielding the following error
Checked Operations coming to our Rescue
To fix such issues, Rust provides a family of checked operations such as checked_sub() and checked_add() etc. to handle such integer underflows and overflows in a programmatically safe way, for example see the operation checked_sub for the primitive type u64 https://doc.rust-lang.org/std/primitive.u64.html#method.checked_sub
Comment: I expect the feature checked_sub to make use of a carry-flag (or similar flag) of the CPU, being set for each arithmetic operation anyway, so all-in-all checked_sub causing very little overhead per arithmetic operation.
Now, let’s use this operation to see how a safe implementation might look like, handling variable input and potential underflows. Here the variables len and size shall be user defined and PAGE_SIZE shall be equal to 4096 .
For example, getting back to the kernel bug. Let’s port the following bad C code snippet (possibly undefined behavior)
#define PAGE_SIZE 4096u
void foo(unsigned int len, unsigned int size) {
if (len > PAGE_SIZE - 2 - size) {
printf("no capacity left\n")
} else {
printf("sufficient capacity %ul\n", PAGE_SIZE - 2 - size);
}
}
the corresponding safe Rust code would look like this, using the operation checked_sub and catching the underflow in the None case branch. Also, please note in the first Some case the additional condition "len > capacity".
const PAGE_SIZE : u64 = 4096;
fn foo(len: u64, size: u64) {
match (PAGE_SIZE - 2).checked_sub(size) {
Some(capacity) if len > capacity => {
println!("no capacity left");
}
Some(capacity) => {
println!("sufficient capacity {}", capacity);
}
None => {
println!("underflow! bad user input!");
}
}
}
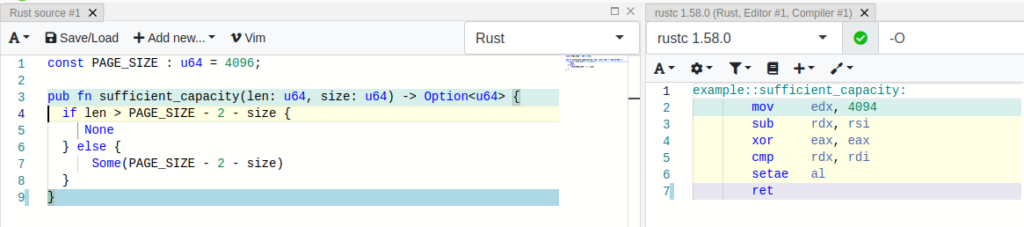
To be able to estimate the costs for the checked variant, the Rust function has been modified slightly in the code below, getting rid of the print-statements. The screenshot of the Compiler Explorer windows shows the corresponding instructions on the right side (please note the instruction setb checking for the carry-flag CF)
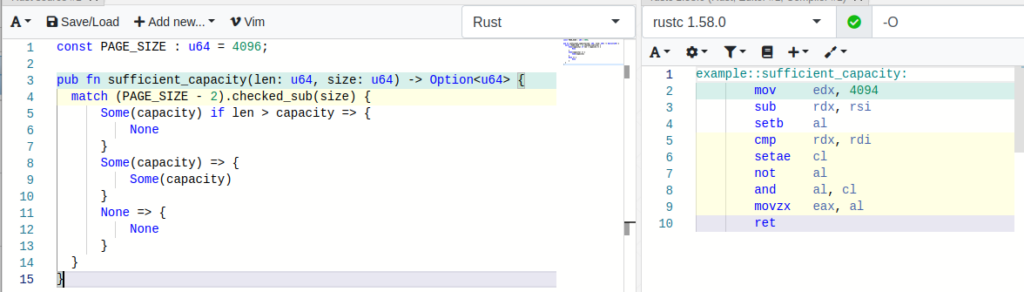
We are able to compare this to the unchecked variant, which may perform arithmetic operations with undefined behavior. The corresponding instructions are shown on the right side of the Compiler Explorer UI. Comparing both, the proportion can be interpreted (naively) as 6 to 9 instructions.
My conclusion is: Arithmetic underflow may occur undiscovered even with Rust (release mode), but rust-clippy provides a mechanism to detect such code segements and Rust provides a standardized API of checked operations to handle these situations with acceptable overhead! So, in any case when dealing with input data, the arithmetic expressions in question should check for underflows or overflows, as demonstrated in the code snipped above using the feature checked_sub() !
PS: for performance reasons, I don’t propose to use checked operations in all expressions, just where affected by inbound data via user input or IO.